The data agent conversation has been running for about two years, and the market has largely converged on a diagnosis: agents fail because they lack context. Not because models aren't capable enough, not because the data isn't there - but because the agent doesn't know how the organization defines its terms, where the sources of truth live, or how to reconcile three different "revenue" numbers from three different tables.
That diagnosis produced a real category. The data context layer - semantic definitions, lineage, business glossary, entity resolution - is being built by a growing set of companies. A16Z recently published a piece around this, aptly titled - “Your Data Agents Need Context” A bunch of companies and approaches were quoted in it. In essence, the 2 tangents that have been taken -
building the active metadata layer for data assets and
building the enterprise knowledge graph for how work and people connect.
Both represent genuine, valuable infrastructure.
But what caught our attention was this part in this piece:
This piece will primarily focus on data context that ties together traditional systems of record.
An equally important and overlapping opportunity is capturing an organization’s decisions and workflow logic so multipurpose agents can be built that are properly grounded in all of an organization’s data and decisioning context.
That sentence is the opening of a different, harder, and arguably, the more consequential category of the problem. It's the problem that Decision AI is built to solve.
The Wall Everyone Keeps Hitting - Why Decision Context Layer Needs to Exist
The failure pattern by now is familiar. Organizations built the data stack. They deployed agents on top of it. Most of them didn't work well for consequential questions. MIT's 2025 report put it plainly: AI deployments fail due to "brittle workflows, lack of contextual learning, and misalignment with day-to-day operations."
The data context layer addresses the most legible part of that failure - data disambiguation, metric standardization, source-of-truth resolution. But even a well-contextualized data agent hits a second wall the moment the question shifts from what happened to why and what should we do next.
Consider a scenario that plays out every quarter in every commercial organization. A head of revenue sits down with the Q2 pipeline report. Coverage is at 2.1x. Target is 3x. She asks the AI analyst: Should we double down on enterprise, or is this a reforecast quarter?
This is where data context runs out of road.
Challenge 1: Trade-off Logic Lives in Human Judgment
Answering the question requires understanding the company's current risk posture, board expectations for the quarter, and how leadership typically resolves the tension between pushing revenue and protecting margin. These decision patterns do not live inside a warehouse or semantic layer. They exist in the judgment of leaders who have been in the room for the last several board reviews.
Challenge 2: Foresight, Not Just Analysis
The system must anticipate what is likely to happen under different scenarios by combining internal signals such as pipeline composition, rep capacity, and deal stage distribution with external factors like competitive activity, seasonality, and category momentum. Historical analysis explains what happened. Foresight reasons from the current state to probable futures and recommends the best next actions.
Challenge 3: Invisible Constraints Shift the Answer
Critical constraints change constantly and rarely appear in structured data systems. The CFO freezing discretionary spend, or a leadership decision to shift marketing budget toward late-stage acceleration, alters what actions are even possible. These constraints exist in meeting notes, Slack discussions, and human memory rather than traditional data infrastructure.
A well-built data context layer gives the agent clean coverage numbers. The metric definition is right. The table is canonical. And the agent still cannot answer the question the head of revenue actually asked.
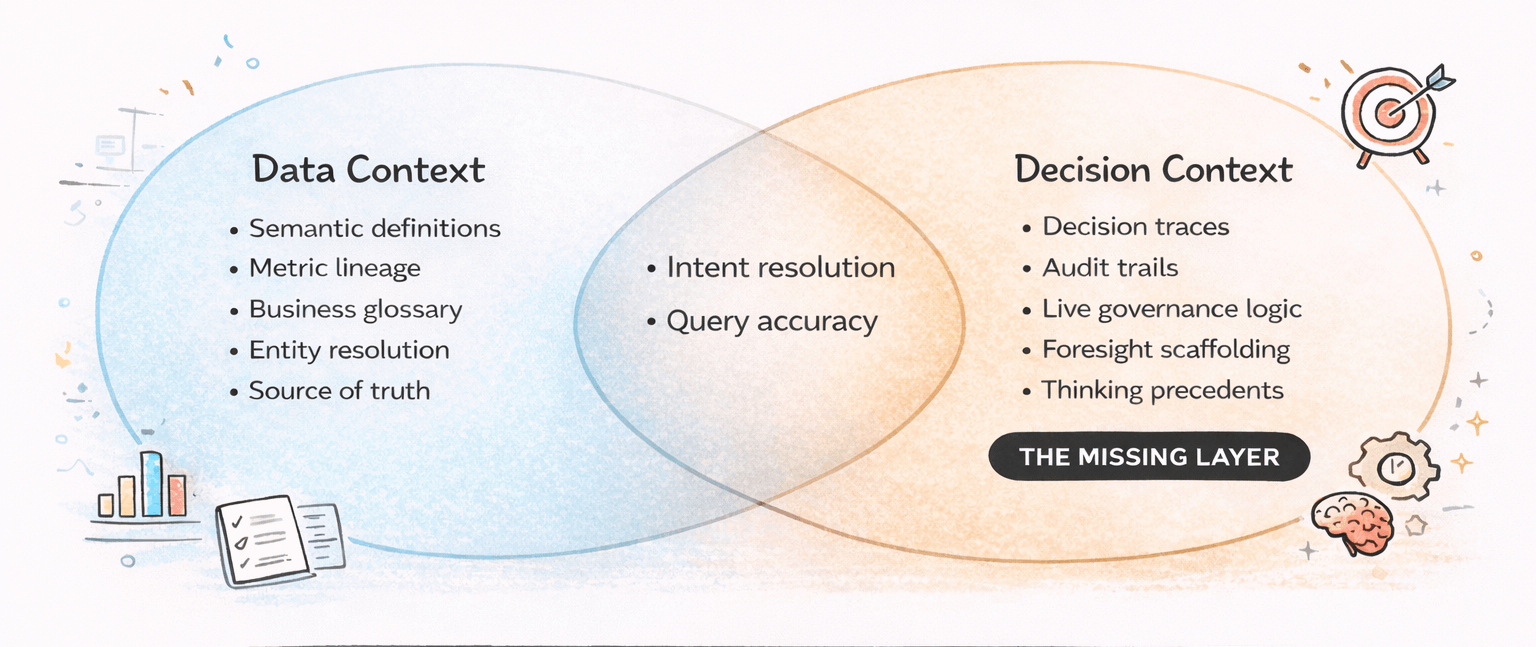
Two Layers That Overlap - One That's Missing
"Data context" versus "Decision context" are not two separate, parallel problems completely. They aren't a MECE pair. They overlap - and the overlap matters.
Decision context doesn't replace data context. It sits on top of it, draws from it, and makes it more powerful. You need both. But the decision layer is the one that turns accurate information into useful guidance - and it's the one that has never existed in any enterprise system.
What data context tools like Atlan and knowledge platforms like Glean are building is genuinely important. Atlan captures the data trace, Glean captures the activity trace. But neither captures the decision trail: what the organization actually decided, under what constraints, with what reasoning, and what it means for the next choice.
That's the gap Decision AI closes. And closing it requires building something that was never quite possible before - not just a better catalog or a semantically richer knowledge graph, but a system that captures organizational cognition in motion.
Why Decision AI Is The Crux of the Context Problem
While building a data context layer is a significant challenge, building a decision context layer is an altogether different kind of engineering and curation problem. The recognition of that is the first step in appreciating the differences that matter:
Temporal instability: Data definitions change slowly. Decision structures in commercial enterprise change with every pricing update, leadership transition, and board-level shift. The RevOps logic that was correct in January may be wrong by April.
No existing artifact to ingest: Data context platforms start with something real - tables, schemas, query history, dbt models. Decision context has no equivalent clean artifact. Decision traces exist in fragments across Notion pages, board decks, calendar invites, and people's memories.
Human judgment can't be configured away: Data context can be substantially automated - platforms like Atlan does it well. Decision context requires human judgment in the loop at the capture layer, not just the verification layer. The people who hold the judgment being formalized are not data engineers. They express themselves in natural language, conditionally, and contextually.
The right architecture has to be bottom-up, not top-down: Hand-modeling decision structures into predetermined schema - the Palantir approach that works well in stable-governance domains - fails in commercial enterprise because the language doesn't hold still long enough to be engineered. The layer has to be discovered from usage and updated through conversation.
It compounds differently: A data context layer becomes more accurate over time as definitions are refined. A decision context layer becomes more intelligent over time - every decision made through it adds to the organizational precedent library, sharpens the governance model, and makes the next decision better-informed. The compounding is qualitatively different.
What the Decision Context Layer Actually Contains
The clearest way to describe this precisely is to describe the a16z framing of the data context layer - which has automated construction, human refinement, and continuous self-updating - and ask: what is the decision equivalent of such a stack?
The answer is a layer with five distinct parts, each of which addresses a specific enterprise problem that gets solved and leads to far better outcomes:
1) Decision traces Every significant decision an organization makes leaves a trail - what was being weighed, who was in the room, what was decided, and what happened next. Today that trail exists in fragments: a memo here, a Slack thread there, an all-hands slide deck, a board update. A decision trace is the structured capture of this - not just that a decision was made, but the context, the constraints, the alternatives considered, and the outcome. This is raw material that no current platform captures at the structural level Decision AI requires.
2) Decision audit trails Beyond capturing individual decisions, the system needs to maintain the full reasoning chain - a verifiable, queryable record of why each decision was made. This is both a governance requirement and a compound intelligence requirement. An organization that can audit its decision history can understand its own patterns, spot where its past reasoning failed, and avoid repeating structural errors. Think of it as version control, but for organizational judgment.
3) Governance logic - live, not static Who has authority over what class of decisions, at what threshold? What trade-offs are resolved by default? What constraints are currently non-negotiable? This is different from a policy document - it's the live, current governance state of the organization, captured in a form the AI can reason against. When the CFO freezes spend, that updates the governance state. When the board changes the growth posture, that updates too. Static policies in documents aren't enough. The system needs the governance state it can reason against in real-time.
4) Foresight scaffolding - scenario context Decision AI's most powerful capability isn't backward analysis. It's the ability to combine internal state data with external market signals to generate probable scenarios and surface the best next actions. For this to work, the system needs a structured understanding of the strategic assumptions currently in play - what bets the organization has made, what market conditions those bets depend on, and which signals would change the calculus. This is not a data problem. It's a cognition problem.
5) Thinking Precedents and their structural lessons Past decisions carry value not as pattern repetition but as structural precedent: this organization, facing a similar trade-off under similar constraints, resolved it this way, for these reasons, and here's what happened. When a Decision AI system can capture and store the reasoning mental model in structured form, it can reason about whether the current situation rhymes - and more importantly, whether the structural conditions that made the prior resolution correct can be applied in context to the present problem.
Taken together, this is a cognition capture problem - and it requires a fundamentally different kind of infrastructure to solve it. [This is what Part 2 of this series examines in depth.]
Where BI Has Been Heading - And Where Decision AI Takes It
THIRTY YEARS OF BUSINESS INTELLIGENCE
Each generation moved the answerable question one step closer — without reaching it
1990s
Reports
What happened last month?
2000s
Dashboards
What is happening right now?
2010s
Self-Serve
What happened in this specific slice?
2020s
Agents
What happened without writing SQL?
Now
Decision AI
Given everything we know,
what should we do?
Business intelligence has been on a thirty-year journey toward a question it was never quite built to answer.
It started with reports - static exports, scheduled queries, PDF summaries delivered to inboxes. Then came dashboards - live data, self-serve exploration, Tableau and Looker and everything that followed. Then self-serve analytics - the promise that anyone in the organization could answer their own data questions. Then the agent era - conversational interfaces on top of the data stack, the promise of asking questions in plain English and getting accurate answers.
Each generation moved the question the system could answer one step closer to what executives actually needed. Reports answered "what happened last month." Dashboards answered "what's happening now." Self-serve answered "what happened in this specific slice." Agents answered "what happened, accurately, without requiring a data analyst to write the SQL."
The question that none of these generations answered - the one that has sat at the end of every BI conversation for thirty years - is: given everything we know, what should we do?
Decision AI is the infrastructure to answer it now. The decision context layer - the traces, the audit trails, the governance logic, the foresight scaffolding, the precedents - gives those facts a grammar of decision making to be reasoned against.
Ranjan Kumar is the Founder and CEO of DecisionX AI, the world’s first self-learning, context-aware Decision Intelligence platform that enables enterprises to make smarter, faster business decisions through agentic AI. A serial entrepreneur and three-time founder with over 17 years of experience, Ranjan previously built Entropik, the world’s first Emotion AI platform with 17 global patent claims. An IIT Kharagpur alumnus, he is widely recognized as a thought leader in enterprise AI, Ontology Engineering, decision reasoning, and AI-driven business transformation.




![Decision AI: Modern Decision Intelligence Stack [Part 2 of 2]](https://cdn.prod.website-files.com/69079d5bc1a99349b566161a/69b293b82dc44eb19c6ba0d7_thumbnail%20short%202.png)

.png)
.png)
.png)
.png)
.png)